NeurIPS 2025 Spotlight | 香港大学提出无需数据标记的ViT密集表征增强方法
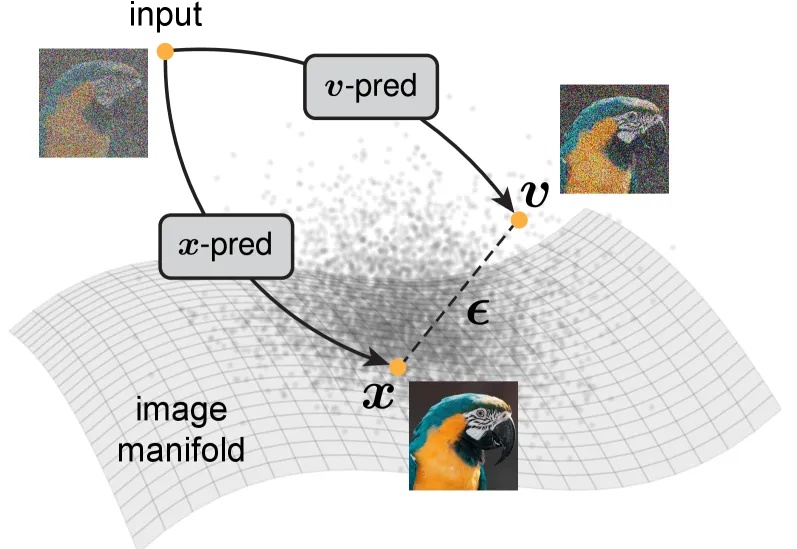
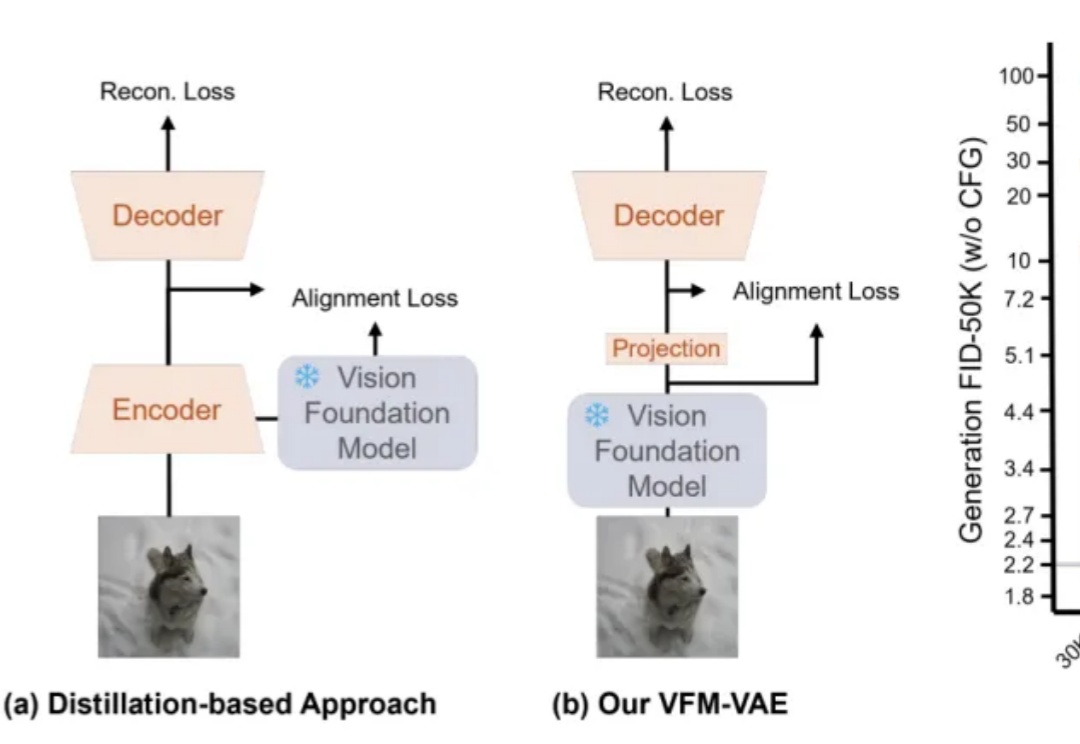
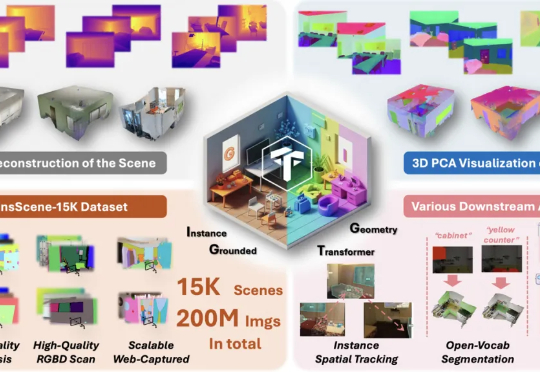
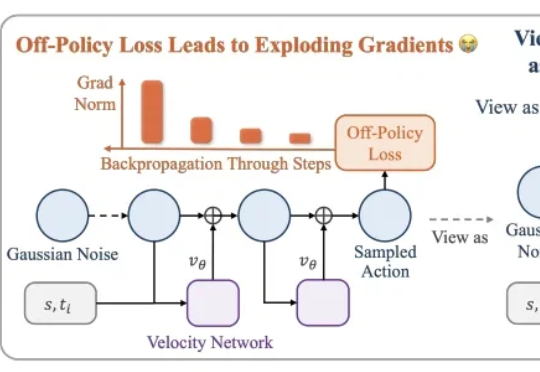
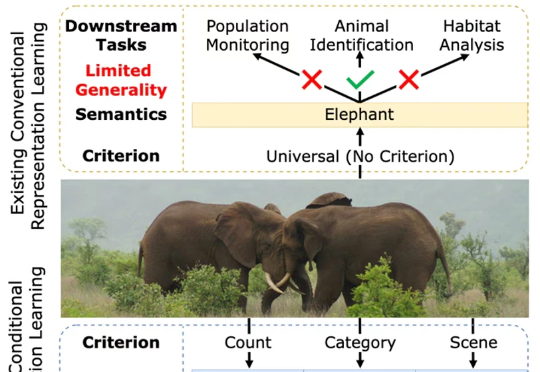
NeurIPS 2025 Spotlight | 香港大学提出无需数据标记的ViT密集表征增强方法在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?
来自主题: AI技术研报
8456 点击 2025-11-20 09:33